Overview
I use engineering as a catch-all for all forms of engineering - too many job titles. My and other engineers' responsibilities span the gamut:
- Data Engineering -> Managing ETL pipelines
- ML Engineering -> Monitoring ML model performance
- Analytics Engineering -> Building DBT models
- Software Engineering -> Creating front-end applications or APIs
- DevOps Engineering -> Updating Jenkins CI/CD pipelines
- Platform Engineering -> Managing cloud infrastructure
- AI Engineering -> Developing with and monitoring LLM (multi-modal) applications.
In the end, Engineers solve problems given toolkits and constraints.
Apache Iceberg
BigQuery now supports Apache Iceberg tables but requires features in pre-release (namely, calling PySpark Stored Procedure). 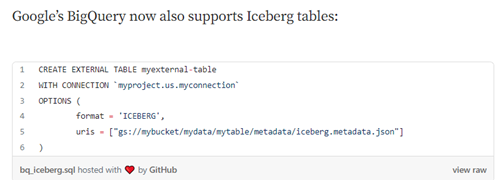
Summary Apache Iceberg is a table format that separates the physical layer (e.g. parquet) from the logical layer. Apache Iceberg's rich metadata layer allows it to efficiently manage large data assets to provide transaction, schema evolution support, scalability, compression, and time travel. 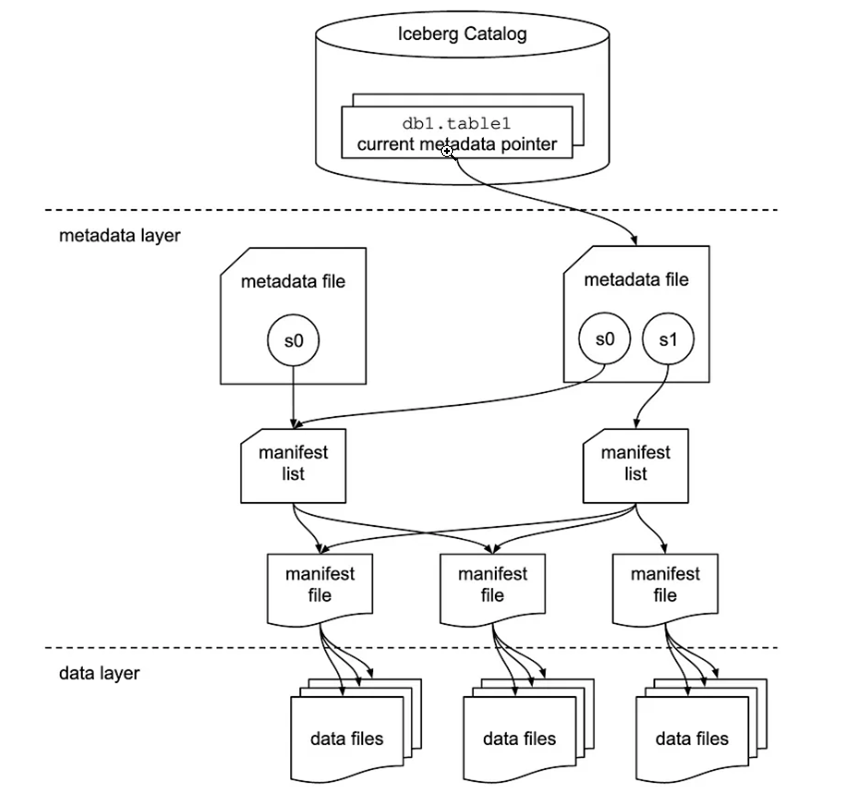
Tabular** is a commercial project from creators. 
DBT
Recently started learning and using DBT at work. There's plenty of great documentation. It's a clever framework for a really common use case for us, which is BigQuery to BigQuery transformations managed by Python and Jinja templating.
The three big concepts that I sell to the team to improve adoption.
- Lineage <-- GCP/BigQuery offers a feature, but it's not turned on
- Modularity <-- Complimentary to BigQuery artifacts, less heavy-handed
- Declarative SQL <-- Especially for testing, specify column & test to run
dbt compile view sql code
The dbt Viewpoint is a great introduction to the project. I've started to adopt this mission statement to the projects that I build:
- Here's the challenge
- Here's how I think about the problem
- Here's my vision