Overview
Collection of notes, links and snippets
Motivation
I accidentally renewed innovator plus which comes with a certification voucher. I can earn an extra $500 credits. As my friend said - close the portfolio out. (Presently I have passed: Cloud Architect, Data Engineer, ML Engineer)
Links & Notes
SRE BookCertification Main PageTraining Path: I generally found this a good place to start before practice questions.
A DevOps Engineer is responsible for defining and implementing best practices for efficient and reliable software delivery and infrastructure management.
Site Reliability Engineering, or SRE, is both a practice and a job role, where engineering directly supports software operations.
Have you ever had a concern about the reliability of your services? Over time, we've standardize our practices to balance our velocity of features with the risk to reliability, both for us and for our customers.
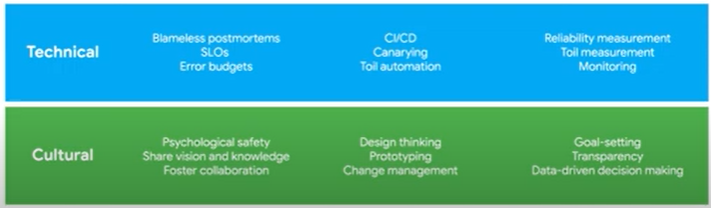
You'll learn about the SRE concepts of service level objectives, error budgets, blamelessness, and psychological safety.
five key areas
- reduce organizational silos
- accept failure is normal
- implement gradual change
- leverage tooling and automation
- measure everything
SRE is a way to implement DevOps.
Error budgets created shared incentive and ownership between developers and SREs.
Developers focus on feature velocity and innovation; operators focus on reliability and consistency.
If you think about SRE as a journey, the first step is to develop service level objectives or SLOs with consequences.
You want to avoid multiplying complexity.
That amount of reliability you are willing to tolerate is your error budget. Error budgets create a common incentive for developers and SREs to find the right balance between innovation and reliability. service-level objectives, or SLOs. SLOs are precise numerical targets for system reliability.
service-level indicators, or SLIs. SLI tells you at any moment in time how well your service is doing SLO is your target for SLIs aggregated over time. SLA, which you are likely familiar with already, is the promise you make about your service's health to your customers. It defines what your business is willing to do if you fail to meet your SLOs. The DevOps pillar of implementing gradual change is practically implemented by SREs in a few different ways to reduce the cost of failure.
Toil is work directly tied to a service that is manual, repetitive, automatable, tactical, without enduring value, or that scales linearly as the service grows.
In Site Reliability Engineering, there are three core practices that align to this pillar, measuring reliability, measuring toil, and monitoring.
Google OKRs stands for Objectives and Key Results. It's a goal-setting framework that Google uses to define and track what the company, teams, and individuals want to achieve. Here's a breakdown of the key aspects:
Objectives: Objectives are ambitious and qualitative descriptions of what a team or individual wants to accomplish within a specific timeframe (usually a quarter). They should be clear, concise, inspiring, and challenge the team to push beyond the ordinary.
Key Results: Key Results are measurable and time-bound metrics that define how you'll know if you're achieving your Objective. They should be specific, ambitious, verifiable, and relevant to the Objective. There are typically 2-5 Key Results for each Objective.
Here's an example to illustrate the concept:
- Objective: Become the leading provider of cloud storage solutions.
- Key Result 1: Increase cloud storage market share by 10% within the quarter.
- Key Result 2: Achieve a 99.9% uptime for all cloud storage services.
- Key Result 3: Launch two new innovative cloud storage features.
Benefits of OKRs:
- Alignment: OKRs help ensure everyone in the company is working towards the same goals.
- Focus and Transparency: They promote clear focus on priorities and create transparency around what matters most.
- Ambitious Goals: By setting ambitious objectives, OKRs encourage innovation and stretch goals.
- Measurable Progress: Key Results provide a way to track progress and measure success objectively.
Here are some additional points to consider about Google OKRs:
- They are typically set on a quarterly basis with regular check-ins to assess progress and make adjustments if needed.
- Not all OKRs are achieved 100% of the time. Google emphasizes the importance of setting ambitious goals and learning from even partially achieved objectives.
- OKRs are not just for companies; they can be adapted for use by teams and individuals to set personal or professional goals.
If you're interested in learning more about Google OKRs, there are several resources available online, including articles, videos, and even books on the topic.
We've looked at site reliability engineering as a three-part journey; SLOs with consequences, make tomorrow better than today, and regulate workload.
Microservices With microservices, the individual components are deployable. To achieve independence on services, each service should have its own datastore. 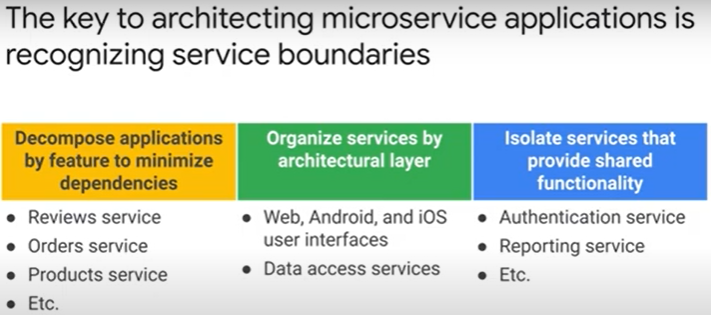
A recognized best practice for designing stateful services is to use backend storage services that are shared by frontend, stateless services.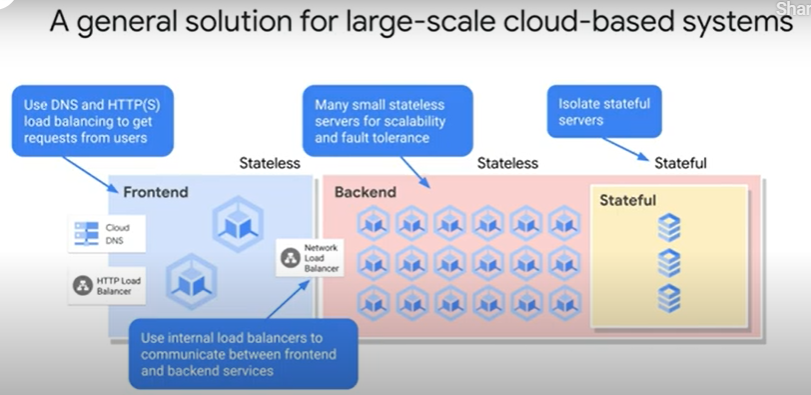
The twelve-factor app is a set of best practices for building web or software-as-a-service applications.
Developed at Google, gRPC is a binary protocol that is extremely useful for internal microservice communication.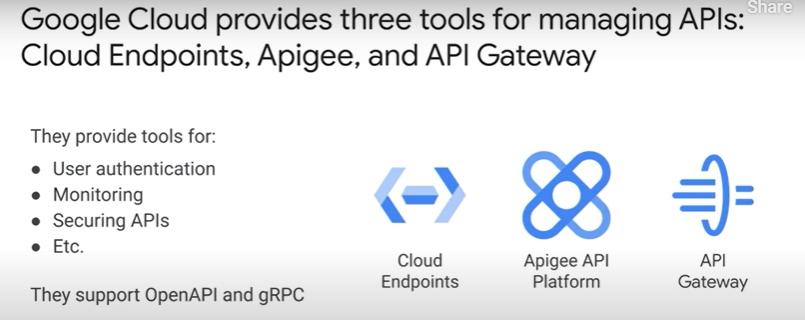
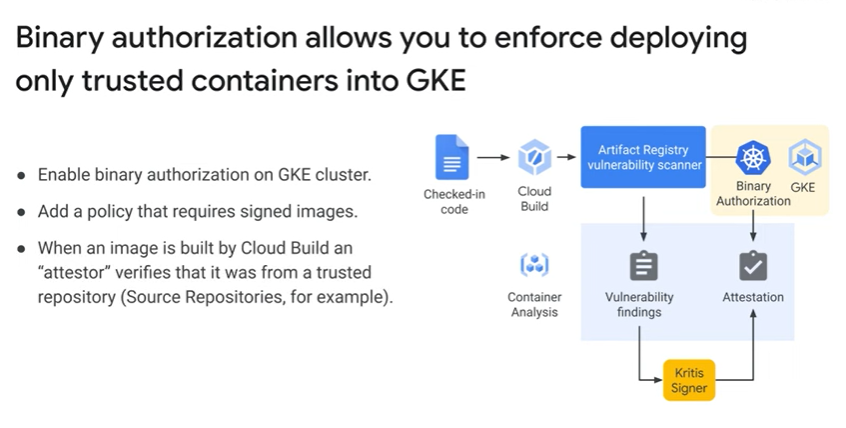
Code and config should be separated, because config varies across deployments but code does not. The true test is whether the repository could be open-sourced without compromising any credentials.
It’s also possible to connect an existing GitHub or Bitbucket repository to Cloud Source Repositories. Connected repositories are synchronized with Cloud Source Repositories automatically.
 Also, you can have multiple networks per project.
Also, you can have multiple networks per project.
These networks are just a collection of regional subnetworks or subnets.
To create custom subnets you specify the region and the internal IP address range, as illustrated in the screenshots on the right. To create custom subnets you specify the region and the internal IP address range
The IP ranges of these subnets don't need to be derived from a single CIDR block, but they cannot overlap with other subnets of the same VPC network.
Once you defined your subnets, machines in the same VPC network can communicate with each other through their internal IP address regardless of the subnet they are connected to.
a single VM can have multiple network interfaces connecting to different VPC networks.
an example of a Compute Engine instance connected to four different networks covering production, test, infra, and an outbound network.
Shared VPC is a centralized approach to multi-project networking, because security and network policy occurs in a single designated VPC network.
Meanwhile, organization network administrators maintain control of resources such as subnets, firewall rules, and routes while delegating the control of creating resources such as instances to service project administrators or developers.
 VPC peering allows private RFC 1918 connectivity across two VPC networks regardless of whether they belong to the same project or the same organization.
VPC peering allows private RFC 1918 connectivity across two VPC networks regardless of whether they belong to the same project or the same organization.
Cloud VPN securely connects your on-premises network to your Google Cloud VPC network through an IPsec VPN tunnel. 
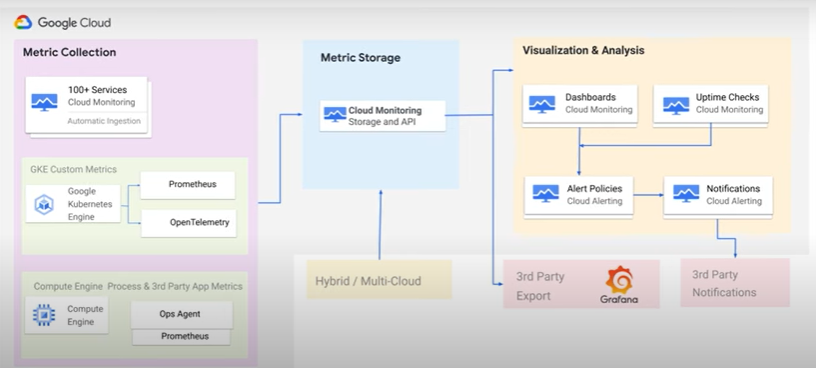
One of the most common uses of Cloud Monitoring is platform monitoring Blackbox monitoring of the platform enables users to get visibility into the performance of their Google Cloud services. 